在 ibireme 的 不再安全的 OSSpinLock 一文中,有一张图简单比较了各种所的加锁性能
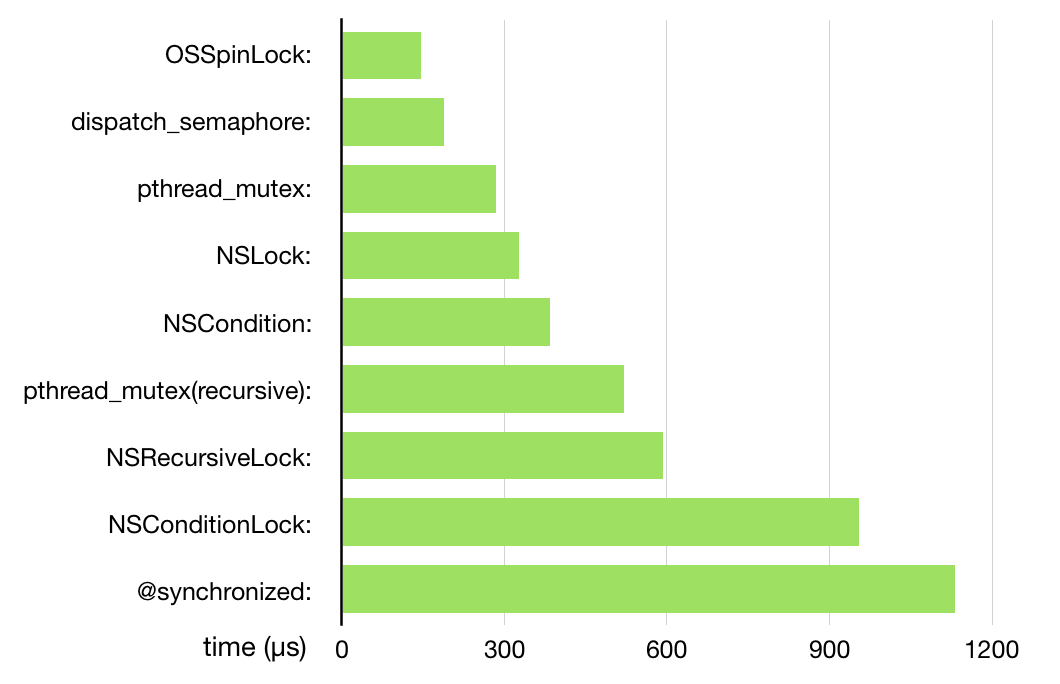 下面根据顺序分析每个加锁的实现原理。注意:加解锁速度并不表示锁的效率,只表示加解锁的操作在执行时的复杂度。
下面根据顺序分析每个加锁的实现原理。注意:加解锁速度并不表示锁的效率,只表示加解锁的操作在执行时的复杂度。
锁之间的关系
忙等类
test_and_set -> OSSpinLock -> os_unfair_lock
休眠类
lll_futex_wait -> GCD信号量
lll_futex_wait -> pthread_mutex
1.加上错误处理 -> NSLock
2.加上条件判断 -> NSCondition + Value -> NSConditionLock
3.加上递归特性 -> NSRecursiveLock
4.加上递归特性、哈希特性 -> @Synchronized(Obj)
OSSpinLock 自旋锁
自旋锁原理
自旋锁的实现思路很简单,理论上来说只要定义一个全局变量,用来表示锁的可用情况即可,伪代码如下:
1
2
3
4
5
6
7
8
bool lock = false; // 一开始没有锁上,任何线程都可以申请锁
do {
while(lock); // 如果 lock 为 true 就一直死循环,相当于申请锁
lock = true; // 挂上锁,这样别的线程就无法获得锁
Critical section // 临界区
lock = false; // 相当于释放锁,这样别的线程可以进入临界区
Reminder section // 不需要锁保护的代码
}
OSSpinLock
忙等锁,会消耗大量的CPU资源。不适合较长时间的任务,因为会导致其他线程忙等。
示例代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
// OSSpinLock
#import <libkern/OSAtomic.h>
// 自旋锁
- (void)testOSSpinLock {
__block OSSpinLock osLock = OS_SPINLOCK_INIT;
// 线程1
dispatch_async(dispatch_get_global_queue(DISPATCH_QUEUE_PRIORITY_HIGH, 0), ^{
NSLog(@"线程1 准备上锁");
OSSpinLockLock(&osLock);
NSLog(@"线程1");
OSSpinLockUnlock(&osLock);
NSLog(@"线程1 解锁完成");
});
// 线程2
dispatch_async(dispatch_get_global_queue(DISPATCH_QUEUE_PRIORITY_BACKGROUND, 0), ^{
NSLog(@"线程2 准备上锁");
OSSpinLockLock(&osLock);
NSLog(@"线程2");
OSSpinLockUnlock(&osLock);
NSLog(@"线程2 解锁完成");
});
}
参考学习中的连接已经说明 OSSpinLock 其实已经不再安全。主要原因在于
当低优先级线程拿到锁时,高优先级线程进入忙等(budy-wait)状态,消耗大量 CPU 时间,从而导致低优先级线程拿不到 CPU 时间,也就无法完成任务并释放锁。这种问题被称为
优先级反转
而且,实际上苹果在iOS10中也不再推荐使用 OSSpinLock,转而使用 os_unfair_lock()
os_unfair_lock
iOS 10.+ 之后添加的,也是属于忙等锁。
示例代码
1
2
3
4
5
6
7
8
9
// os_unfair_lock
#import <os/lock.h>
os_unfair_lock_t unfairlock = &(OS_UNFAIR_LOCK_INIT);
os_unfair_lock_lock(unfairlock);
NSLog(@"os_unfair_lock 执行");
os_unfair_lock_unlock(unfairlock);
dispatch_semaphore GCD信号量
加锁时会把信号量的值减一,并判断是否大于零。如果大于零,说明不用等待,立刻执行。在没有等待的情况下,性能比 pthread_mutex 高,但是一旦有等待的情况出现,性能就会急剧下降。其优势在于等待时不会消耗 CPU 资源,会进行线程休眠。
然而,主动让出时间片(线程休眠)并不总是代表效率高,让出时间片会导致操作系统切换到另一个线程,这类上线文切换一般需要10ms左右,且至少需要两次切换才能切换回本线程。如果小于20ms,忙等就比线程睡眠更加高效了。
示例代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
// 信号量
- (void)testDispatch_semaphore {
dispatch_semaphore_t signal = dispatch_semaphore_create(1);
dispatch_time_t timeout = dispatch_time(DISPATCH_TIME_NOW, 3.0f * NSEC_PER_SEC);
// DISPATCH_TIME_FOREVER 不限时
// 线程1
dispatch_async(dispatch_get_global_queue(DISPATCH_QUEUE_PRIORITY_DEFAULT, 0), ^{
NSLog(@"线程1 等待ing");
dispatch_semaphore_wait(signal, timeout); // signal 值 - 1
sleep(2);
NSLog(@"线程1");
dispatch_semaphore_signal(signal); // signal 值 + 1
NSLog(@"线程1 发送信号");
});
// 线程2
dispatch_async(dispatch_get_global_queue(DISPATCH_QUEUE_PRIORITY_DEFAULT, 0), ^{
NSLog(@"线程2 等待ing");
dispatch_semaphore_wait(signal, timeout); // signal 值 - 1
NSLog(@"线程2 sleep");
sleep(2);
NSLog(@"线程2");
dispatch_semaphore_signal(signal); // signal 值 + 1
NSLog(@"线程2 发送信号");
});
}
pthread_mutex 互斥锁
pthread 表示 POSIX thread,定义了一组跨平台的线程相关的API,pthread_mutex 表示互斥锁。互斥锁的实现原理与信号量非常相似,不是使用忙等,而是阻塞线程并睡眠,需要进行上线文切换。
示例代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
// pthread
#import <pthread.h>
// pthread_mutex 互斥锁
- (void)testPthread_mutex {
static pthread_mutex_t pLock;
pthread_mutex_init(&pLock, NULL);
// 线程1
dispatch_async(dispatch_get_global_queue(DISPATCH_QUEUE_PRIORITY_DEFAULT, 0), ^{
NSLog(@"线程1 准备上锁");
pthread_mutex_lock(&pLock);
NSLog(@"线程1");
sleep(3);
pthread_mutex_unlock(&pLock);
NSLog(@"线程1 释放锁");
});
// 线程2
dispatch_async(dispatch_get_global_queue(DISPATCH_QUEUE_PRIORITY_HIGH, 0), ^{
NSLog(@"线程2 准备上锁");
pthread_mutex_lock(&pLock);
NSLog(@"线程2");
pthread_mutex_unlock(&pLock);
NSLog(@"线程2 释放锁");
});
}
\/ 一般情况下,一个线程只能申请一次锁,也只能在获得锁的情况下才能释放锁,多次申请锁或者释放未获得的锁都会导致崩溃。假设在已经获得锁的情况下再次申请锁,线程会因为等待锁的释放而进入睡眠状态,因此就不可能再释放锁,从而导致死锁。
然而这种情况会经常发生,比如某个函数申请了锁,在临界区内又递归调用了自己。幸运的是 pthread_mutex 支持递归锁,也就是允许一个线程递归的申请锁。
pthread_mutex 递归锁
示例代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
// pthread_mutex 递归锁
- (void)testPthread_mutex_recursive {
static pthread_mutex_t pLock;
// 定义锁的属性
pthread_mutexattr_t attr;
pthread_mutexattr_init(&attr);
pthread_mutexattr_settype(&attr, PTHREAD_MUTEX_RECURSIVE); // 设置为递归锁
pthread_mutex_init(&pLock, &attr);
pthread_mutexattr_destroy(&attr);
// 线程1
dispatch_async(dispatch_get_global_queue(DISPATCH_QUEUE_PRIORITY_DEFAULT, 0), ^{
static void (^RecursiveBlock)(int);
RecursiveBlock = ^(int value) {
pthread_mutex_lock(&pLock);
if (value > 0) {
NSLog(@"value: %d", value);
sleep(1);
RecursiveBlock(value - 1);
}
};
NSLog(@"线程1 准备上锁");
RecursiveBlock(5);
NSLog(@"线程1");
pthread_mutex_unlock(&pLock);
NSLog(@"线程1 解锁");
});
// 线程2
dispatch_async(dispatch_get_global_queue(DISPATCH_QUEUE_PRIORITY_DEFAULT, 0), ^{
NSLog(@"线程2 准备上锁");
pthread_mutex_lock(&pLock);
NSLog(@"线程2");
pthread_mutex_unlock(&pLock);
NSLog(@"线程2 解锁");
});
}
递归锁比较安全,可以认为同一线程加且仅加一次锁,重复加锁不会造成死锁。无论同一线程加锁多少次,解锁1次即可。
互斥锁的实现
互斥锁在申请锁时,调用了pthread_mutex_lock方法,它在不同的系统上实现各有不同,有时候它的内部是使用信号量来实现,即使不用信号量,也会调用到lll_futex_wait函数,从而导致线程休眠。
上面提到说,如果线程等待的临界区很短,忙等的效率也许更高,所以在有些版本的实现中,会首先尝试一定次数(比如1000次)的test and set,这样可以在错误使用互斥锁时提高性能。
另外,由于 pthread_mutex有多种类型,可以支持递归锁等,因此在申请加锁时,需要对锁的类型加以判断,这也就是为什么它和信号量的实现类似,但效率略低的原因。
NSLock 和 NSRecursiveLock
NSLock /NSRecursiveLock 是 Objective-c 以对象的形式暴露给开发者的一种锁。
示例代码
1
2
3
4
5
6
7
8
9
10
11
12
// NSLock
- (void)testNSLock {
NSLock *lock = [NSLock new];
[lock lock];
NSLog(@"加锁运行");
[lock unlock];
NSRecursiveLock *recursiveLock = [NSRecursiveLock new];
[recursiveLock lock];
NSLog(@"加锁运行");
[recursiveLock unlock];
}
这里的 NSLock 和 NSRecursiveLock 都是封装的互斥锁 pthread_mutex。
NSLock 只是在内部封装了一个 pthread_mutex,属性为 PTHREAD_MUTEX_ERRORCHECK,他会损失一定的性能换来错误提示。理论上来说,NSLock 和 pthread_mutex 拥有相同的运行效率,实际由于封装的原因会略慢一点。由于有缓存存在,相差不会很多。
NSRecursiveLock 与 NSLock 的区别在于内部封装的 pthread_mutex_t 对象的类型不同,NSRecursiveLock 的类型为 PTHREAD_MUTEX_RECURSIVE。
NSCondition
它通常用于表明共享资源是佛偶可被访问或者确保一系列任务能按照指定的执行顺序执行。如果一个线程视图访问一个共享资源,而正在访问该资源的线程将其条件设置为不可访问,那么该线程会被阻塞,知道正在访问该资源的线程将访问条件更改为可访问状态或者说给被阻塞的线程发送信号后,被阻塞的线程才能正常访问这个资源。
NSCondition 的底层是通过条件变量(condition variable) pthread_cond_t 来实现的。条件变量有点像信号量,提供了线程阻塞与信号机制,隐藏可以用来阻塞某个线程,并等待某个数据就绪,随后唤醒线程。比如常见的 生产者–消费者模式。
NSConditionLock
NSConditionLock 借助 NSCondition 来实现,它的本质就是个【生产者–消费者】模型。’条件被满足’可以理解为生产者提供了新的内容。NSConditionLock 的内部持有一个 NSCondition 对象,以及 _condition_value 属性。
示例代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
// NSConditionLock
- (void)testNSConditionLock {
NSConditionLock *cLock = [[NSConditionLock alloc] initWithCondition:0];
// 线程1
dispatch_async(dispatch_get_global_queue(DISPATCH_QUEUE_PRIORITY_DEFAULT, 0), ^{
NSLog(@"线程1 加锁");
[cLock lockWhenCondition:1];
NSLog(@"线程1");
[cLock unlockWithCondition:3];
NSLog(@"线程1 解锁");
});
// 线程2
dispatch_async(dispatch_get_global_queue(DISPATCH_QUEUE_PRIORITY_LOW, 0), ^{
NSLog(@"线程2 加锁");
if ([cLock tryLockWhenCondition:0]) {
NSLog(@"线程2");
[cLock unlockWithCondition:1];
NSLog(@"线程2 解锁");
} else {
NSLog(@"失败");
}
});
// 线程3
dispatch_async(dispatch_get_global_queue(DISPATCH_QUEUE_PRIORITY_HIGH, 0), ^{
NSLog(@"线程3 加锁");
[cLock lockWhenCondition:3];
NSLog(@"线程3");
[cLock unlockWithCondition:2];
NSLog(@"线程3 解锁");
});
}
上述代码会按照:线程2 > 线程1 > 线程3 的顺序执行。
@synchronized
示例代码
1
2
3
@synchronized (self) {
NSLog(@"加锁运行");
}
只要关键字中的对象一致,则多个线程会互斥等待程序运行完成。
@synchronized 实际上是把修饰对象当做锁来使用。这是通过一个哈希表来实现的,OC在底层使用了一个互斥锁的数组(可以理解为锁池),通过对对象去哈希值来得到对应的互斥锁。
一些多线程的基础知识
时间片轮转调度算法
了解多线程加锁必须知道时间片轮转调度算法,才能深切理解其原理,性能瓶颈。
现代操作系统在管理普通线程时,通常采用时间片轮转算法(Round Robin,简称RR)。每个线程会被分配一段时间片(quantum),通常在10-100毫秒左右。当线程用于属于自己的时间片以后,就会被系统挂起,放入等待队列中,知道下一次被分配时间片,如果线程在时间片结束前阻塞或者结束,则CPU当即进行切换。由于线程切换需要时间,如果时间片太短,会导致大量CPU时间浪费在切换上;而如果这个时间太长,会使得其他线程等待太久。
原子操作
狭义上的原子操作表示一条不可打断的操作,也就是说线程在执行操作过程中,不会被操作系统挂起,而是一定会执行完(理论上拥有CPU时间片无限长)。在单处理器环境下,一条汇编指令显然是原子操作,因为中断也要通过指令来实现,但一句高级语言的代码却不是原子的,因为它最终是由多条汇编语言完成,CPU在进行时间片切换时,大多都会在某条代码的执行过程中。 但在多核处理器下,则需要硬件支持,没了解过具体实现。
自旋锁和互斥锁
都属于CPU时间片算法下的实现保护共享资源的一种机制。都实现互斥操作,加锁后仅允许一个访问者。
区别在于自旋锁不会是线程进入wait状态,而是通过轮询不停查看是否该自旋锁的持有者已经释放的锁;对应的,互斥锁在出现锁已经被占用的情况下会进入wait状态,CPU会当即切换时间片。
自旋锁实现原理
1
2
3
4
5
6
7
lock = 0;
do{
while(test_and_set(&lock));
临界区
lock = 0;
其余部分
} while(1)
test_and_set用来保证条件判断的原子性操作,lock为旗标。 自旋锁的一大缺陷是会使得线程处于忙等状态。因为如果临界区执行时间过长,其它线程就会在当前整个时间片一直处于忙等状态,浪费大量CPU时间。所以,如果临界区时间很短,可以使用自旋锁,否则建议使用互斥锁。
互斥锁的实现原理
互斥锁在出现锁的争夺时,未获得锁的线程会主动让出时间片,阻塞线程并睡眠,需要进行上下文切换,CPU会切换其它线程继续操作。 主动让出时间片并不总是代表效率高。让出时间片会导致操作系统切换到另一个线程,这种上下文切换通常需要 10 微秒左右,而且至少需要两次切换。如果等待时间很短,比如只有几个微秒,忙等就比线程睡眠更高效。
信号量的实现
1
2
3
4
5
6
7
int sem_wait (sem_t *sem) {
int *futex = (int *) sem;
if (atomic_decrement_if_positive (futex) > 0)
return 0;
int err = lll_futex_wait (futex, 0);
return -1;
)
信号量和互斥锁类似,都是在获取锁失败后线程进入wait状态,CPU会切换时间片。 信号量在最终都是调用一个sem_wait方法,并原子性的判断信号量,如果对其-1后依然大于0,则直接返回,继续临界区操作,否则进入等待状态。
多线程中的常见术语名词
互斥锁(mutex)
提供共享资源互斥访问的锁。一个互斥锁同一时间只能被一个线程拥有。视图获取一个已经被其他线程拥有的互斥锁,会把当前线程置于休眠状态,直到该锁被其他线程释放并让当前线程获取。
####### 递归锁(recursive lock)
可以被同一线程多次锁住的锁。
信号量(semaphore)
一个受保护的变量,它限制共享资源的访问。互斥锁(mutexes)和条件(conditions)都是不同类型的信号量。
条件(condition)
一个用来同步资源访问的结构。线程等待某一个条件来决定是否被允许继续运行,知道其他线程显示的给该条件发送信号
临界区(critical section)
同一时间只能不被一个线程执行的代码。
输入源(input source)
一个线程的异步事件源。输入源可以是基于端口的或者手工触发,并且必须被附加到某一个线程的run loop上面。
线程(thread)
进程里面的一个执行过程流。每个线程都有它自己的栈空间,但除此之外同一进程的其他线程共享内存。
主线程(main thread)
当创建进程时一起创建的特定类型的线程。当程序的主线程退出,则程序即退出。
可连接的线程(join thread)
退出时资源不会被立即回收的线程。可连接的线程在资源被回收之前必须被显示脱离或由其他线程连接。可连接线程提供了一个返回值给连接它的线程。
操作对象(operation object)
NSOperation 类的示例。操作对象封装了和某一任务相关的代码到一个执行单元里面。
操作队列(operation queue)
NSOperationQueue 类的示例。操作队列管理操作对象的执行。